


The glitch in AI text-to-image generators
As it turns out, direct copying does happen, but under what conditions?

In the May 2023 research paper “Understanding and Mitigating Copying in Diffusion Models” the authors provide further research on their 2022 paper and experiment with possible causes and mitigations in the anomalies where image generators reproduce exact copies of source training data (which they’re not supposed to do). It’s a technical paper and much of it is beyond me except the conclusions:
multiples of duplicate images in the training data increase the chances of image duplication
multiple instances of duplicate captions are a major factor in increasing the chances of image duplication
highly specific captions seem to stick in the memory of the diffusion models, increasing the chance of image duplication
very simple images seem to have higher incidences of image duplication
How prevalent are these image duplications? That is hard to say, but it could be as high as 1.2%, though I suspect that most of those duplications are from prompts that reference specific, extremely popular and internet-prevalent images (see below). Having spent the past year generating thousands of images, I find 1.2% hard to believe if one is not actually trying to invoke copyrighted images.
Where claims of the risks are highly exaggerated
I closely follow Gary Marcus, who writes a lot about AI and is well known in those circles1. I usually agree with his take on things, and look forward to my subscribed emails. On Jan. 6, 2024, he and Reid Southen wrote a lengthy article, “Generative AI Has a Visual Plagiarism Problem” in the tech publication IEEE Spectrum. In it, they reference both academic papers, above, and discuss what they term “plagiaristic outputs” from both LLMs (Language Learning Models, like Chat-GPT) and image-generating models (which does not have a handy acronym, but should be IGMs, no?) like Midjourney v.6.02 (the default version is 5.2, which I use almost daily).
I’m going to question this article on the prevalence and significance of this plagiarism (where plagiarism means making an exact or near-exact copy of something) in, specifically, Midjourney, while acknowledging that it’s documented as happening despite having never seen it myself.
Intent to copy hugely famous things
I am going to dismiss out of hand the first part of their argument, that it reproduces, near exactly, images from very popular movies from specific prompts, mostly because the requests show intent to copy specific things, and the internet is saturated with those specific things; i.e. this is cherrypicking, or shooting fish in a barrel.





In contrast, when I ask for something similarly specific from a pre-digital famous movie like a) “Knife in the Water” by Polanski, or b) “The Graduate”, the results are abysmal3.

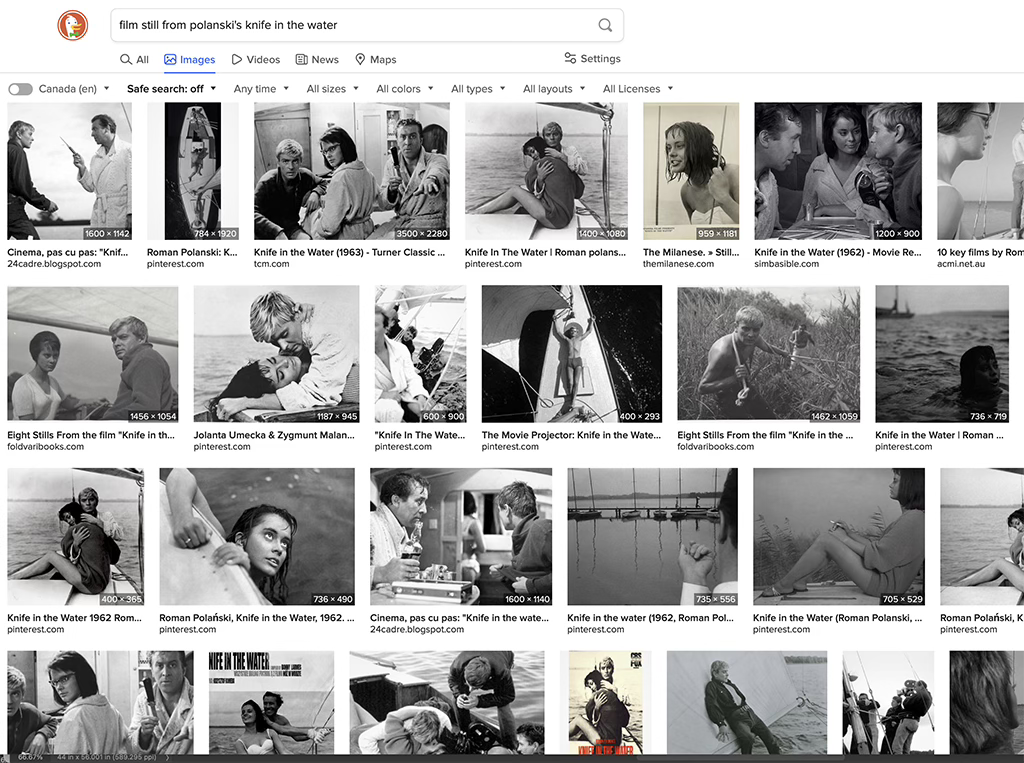

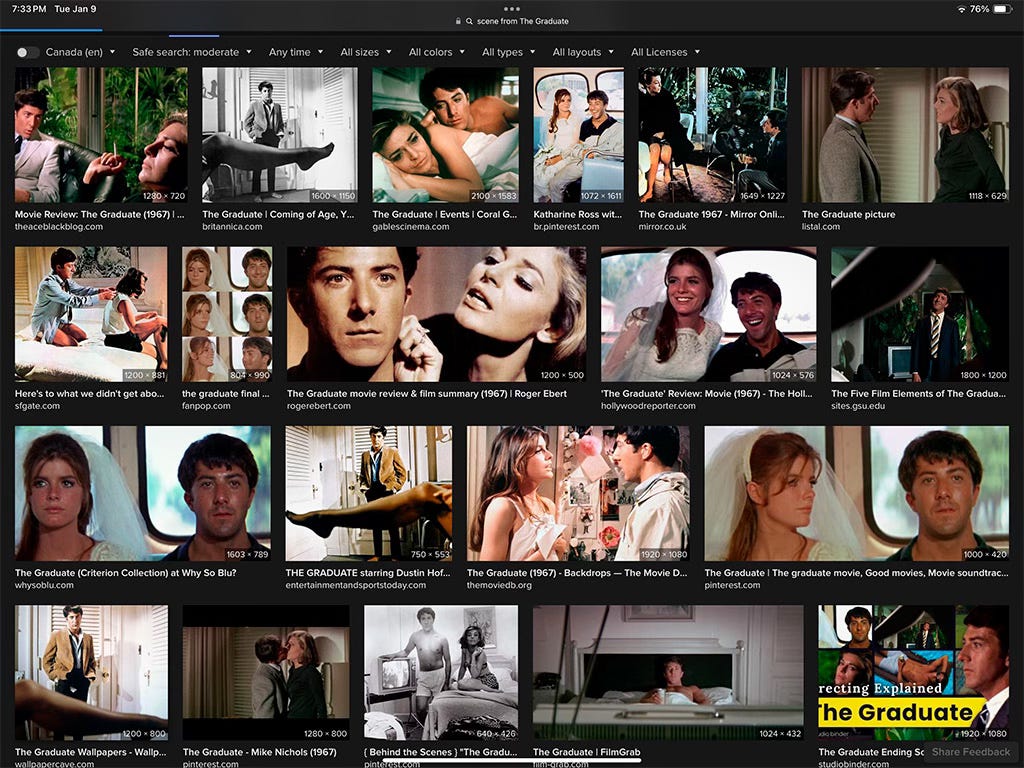
For “The Graduate” I even prompted it for what appears to be its most famous still, and it hadn’t a clue.


Some things, such as Star Wars’ C3PO are so famous that it’s actually hard to get around them, and in the interests of imagination, it is genuinely appalling that asking for a “science fiction droid” will often get you C3PO (as of this writing it is probably harder to do, as Midjourney will likely have very recently patched their system to reduce or eliminate that outcome since Marcus and Southen’s article came out).
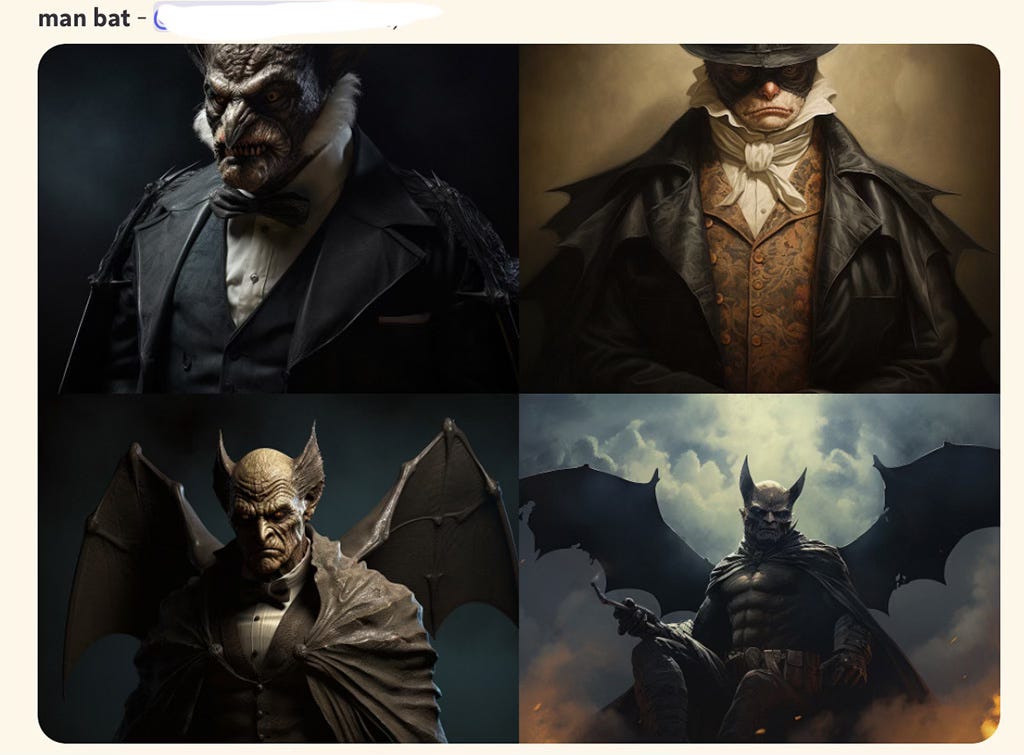
Similarly, “Bat man” will get you:
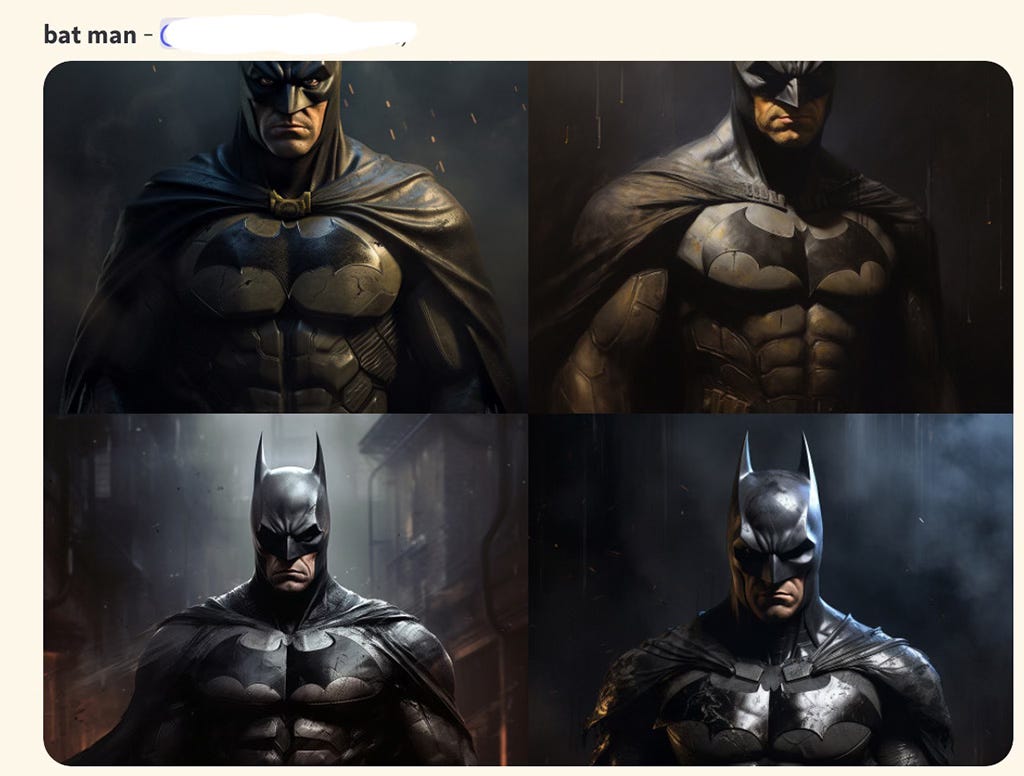
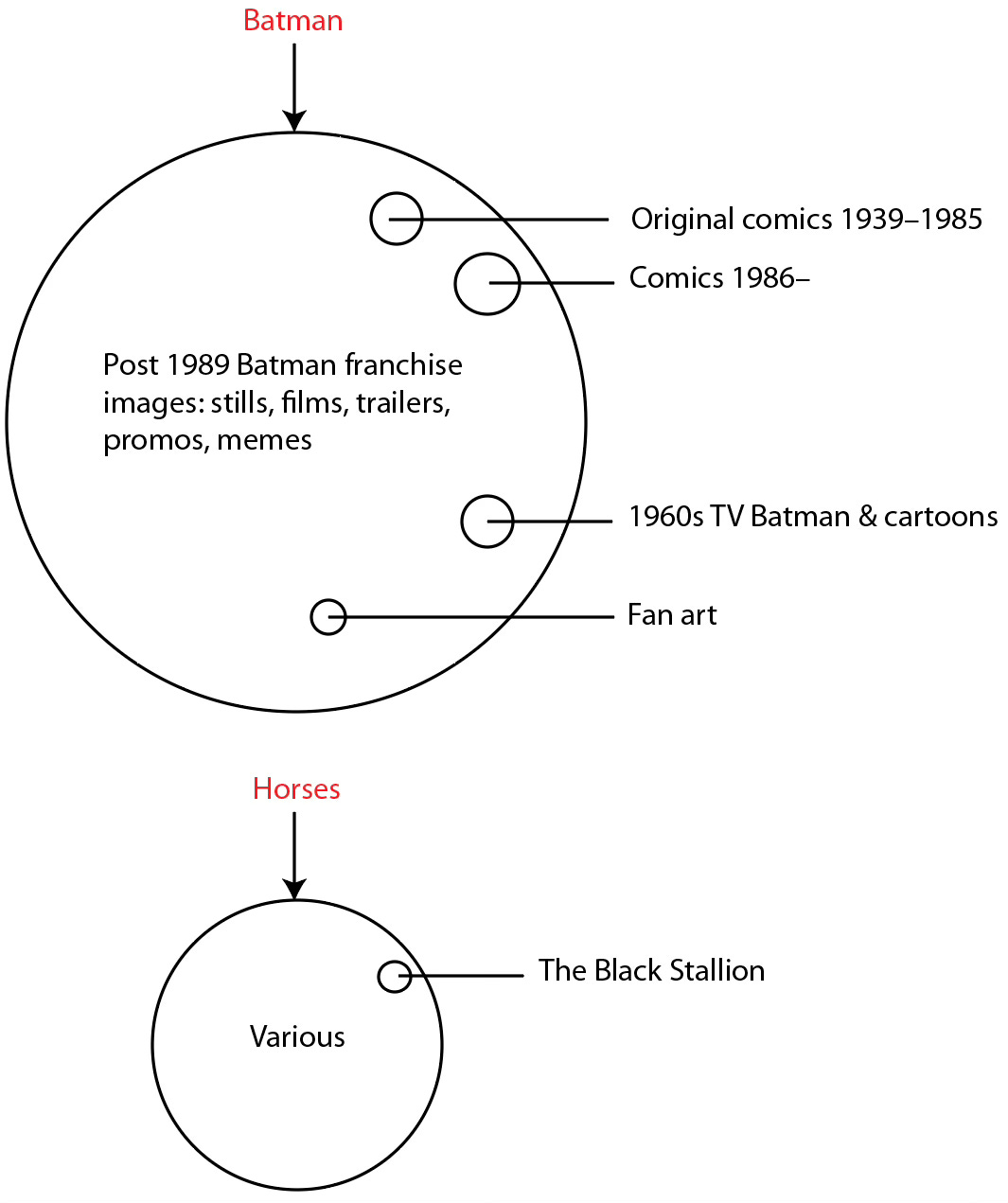
The reason for this, I believe, is the sheer abundance of images, clips and memes (most of them copyright infringements themselves, see below) from the Batman franchise over the past 20 years. In the following unscientific image (by me) you can see how I think the collection of Batman images is on the internet, where the vast majority is from the contemporary franchise, and relatively few are from other sources. This compared to say “horses” where the vast majority are from disparate sources and thus far less likely to get an exact match of a horse image.
(And what if you really wanted an original image of a bat-like man or bat-man hybrid? Easy.):
What does this mean for Midjourney, et al.?
They are probably going to get their asses sued by some very big corporations with very deep pockets.
What does it mean for the rest of us?
Here’s where M&S & I really part ways. I believe they vastly over-emphasise the risk that a user of Midjourney (in particular) could be sued for unwittingly summoning an exact replica of a copyrighted image. They quote an X (Twitter) account thus:
“X user @Nicky_BoneZ addresses this vividly:
… everyone knows what Mario looks Iike. But nobody would recognize Mike Finklestein’s wildlife photography. So when you say “super super sharp beautiful beautiful photo of an otter leaping out of the water” You probably don’t realize that the output is essentially a real photo that Mike stayed out in the rain for three weeks to take.”
My first thought was “Who is Mike Finklestein?” An internet search found no photographers by the name Finklestein, but several by the name Finkelstein, only one of whom does wildlife photography, but I could find no pictures of otters in his portfolio. I also searched “super super sharp beautiful beautiful photo of an otter leaping out of the water” (Note, the first 3 results are cartoonish digital images from something called “dreamstime.com”):
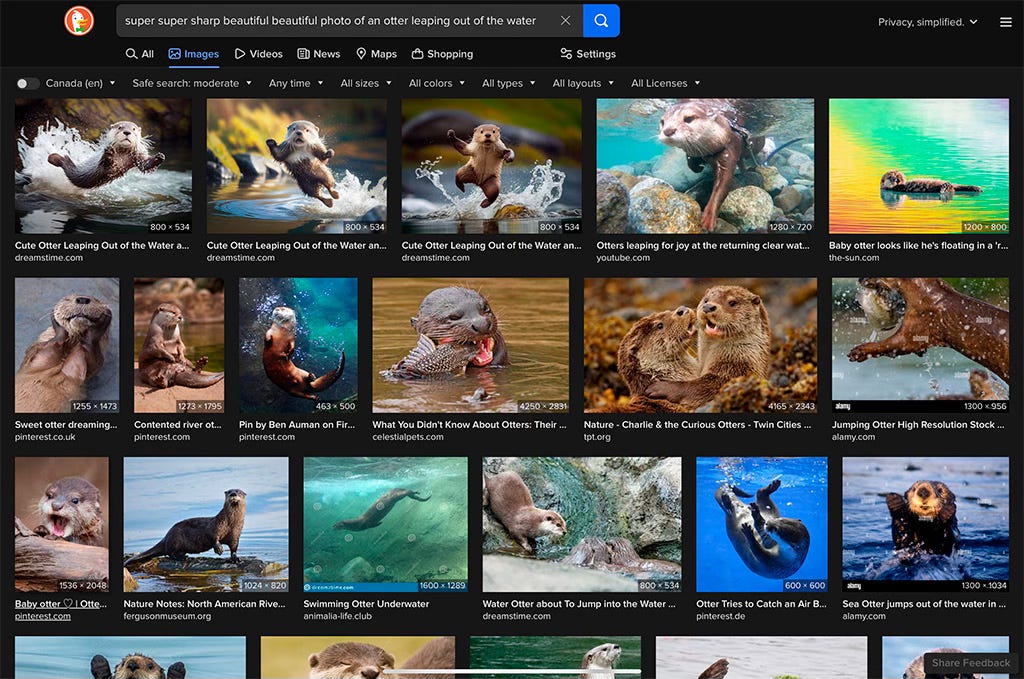
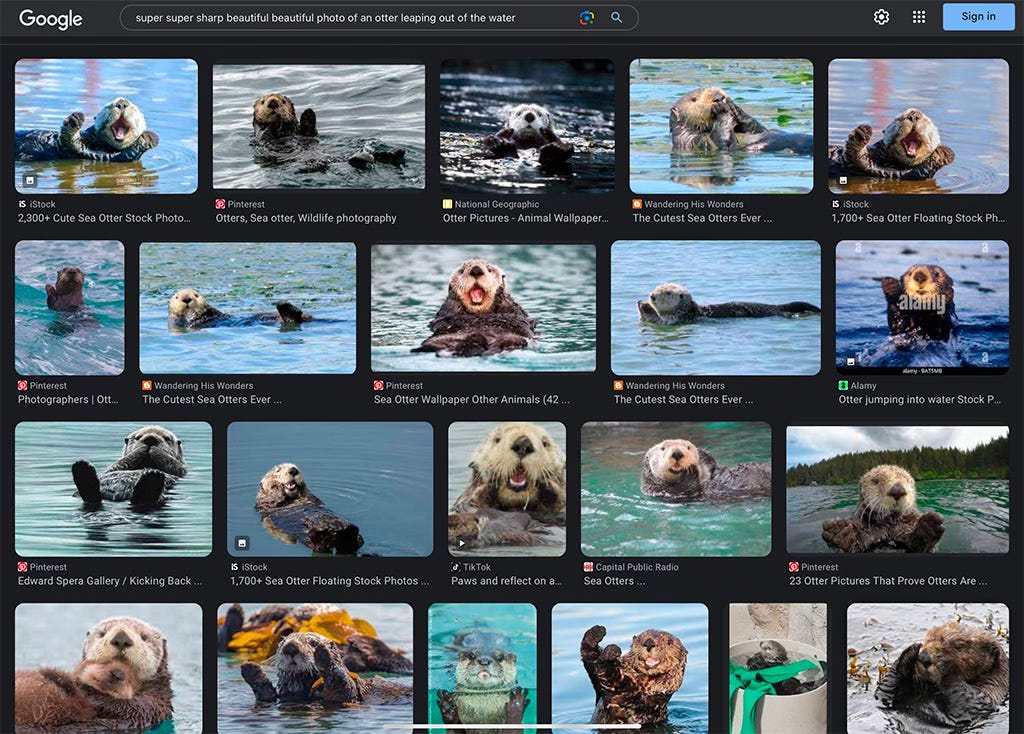
None seemed to be by a Mike Finkle/elstein, at least none of the ones where the otter is “leaping” (I didn’t check the ones that weren’t). I also searched “Mike Finklestein otter photo” with no definitive result. I then generated some images in Midjourney v6.0 from the same prompt (I’m only showing the first result but as with the other examples I’ve made, I ran the prompt a few times, with similar results).

(Midjourney strongly favours face-forward images.)
So this is just a random, untested claim by some random person on Twitter that is being used as “evidence” that this can happen. Actually M&S have more than one reference to claims by people on Twitter:
“Another X user similarly discussed an example of a friend who created an image with a prompt of “man smoking cig in style of 60s” and used it in a video; the friend didn’t know they’d just used a near duplicate of a Getty Image photo of Paul McCartney.”
Without actually seeing this near duplicate and the actual prompt that created it, I’m afraid I would throw that out as any sort of evidence.
This brings me back to testing some famous-but-not-Batman-famous images, this time in Midjourney v6.0 (which is what most of the fuss seems to be about).
The very famous artist Ed Ruscha’s most well-known work is evidenced by a search for it:
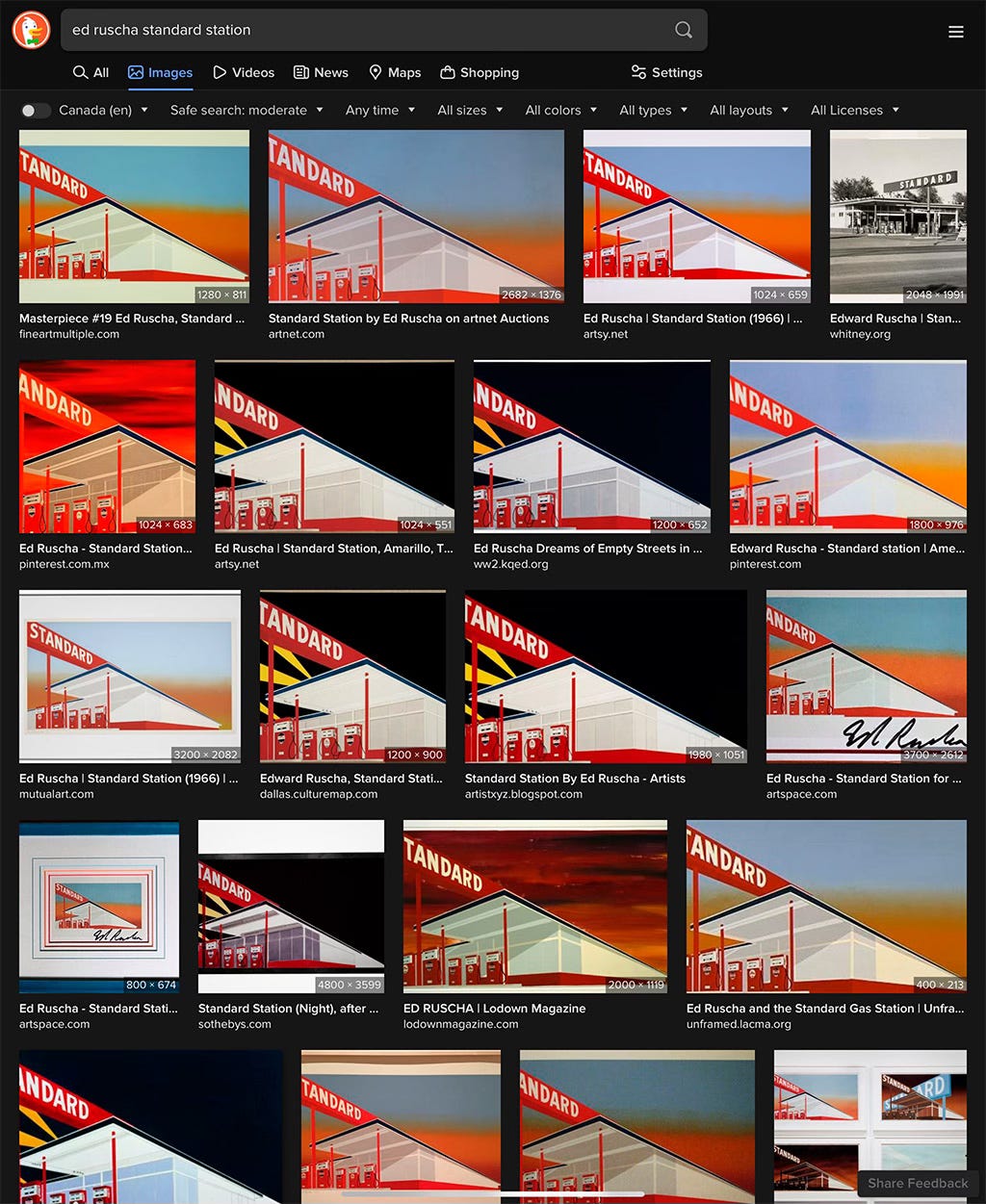
Specifically asking for it gets pathetic results, though given the 3 results with a dusk sky, it seems Midjourney knows something about it.

“Accidentally” asking for it with “2 color perspective image of a Standard Oil gas station” shows no propensity for referencing the famous artwork.

For something more populist, Saul Bass’s poster and titling for “The Man with the Golden Arm” is extremely well known, and has been ripped off (or been referenced, in “homage”) by designers young and old:
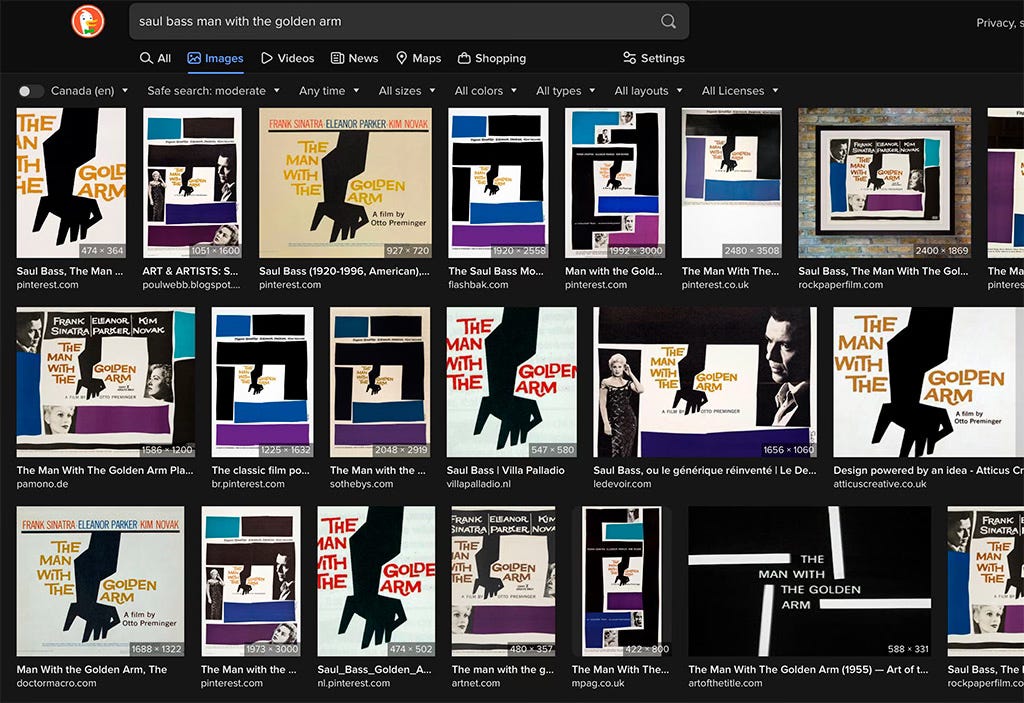
If you “innocently” wanted help with redesigning a poster for this movie (which only a complete hack would do), Midjourney is unaware of this famous influence. Nor is it any less clueless when specifically prompted:
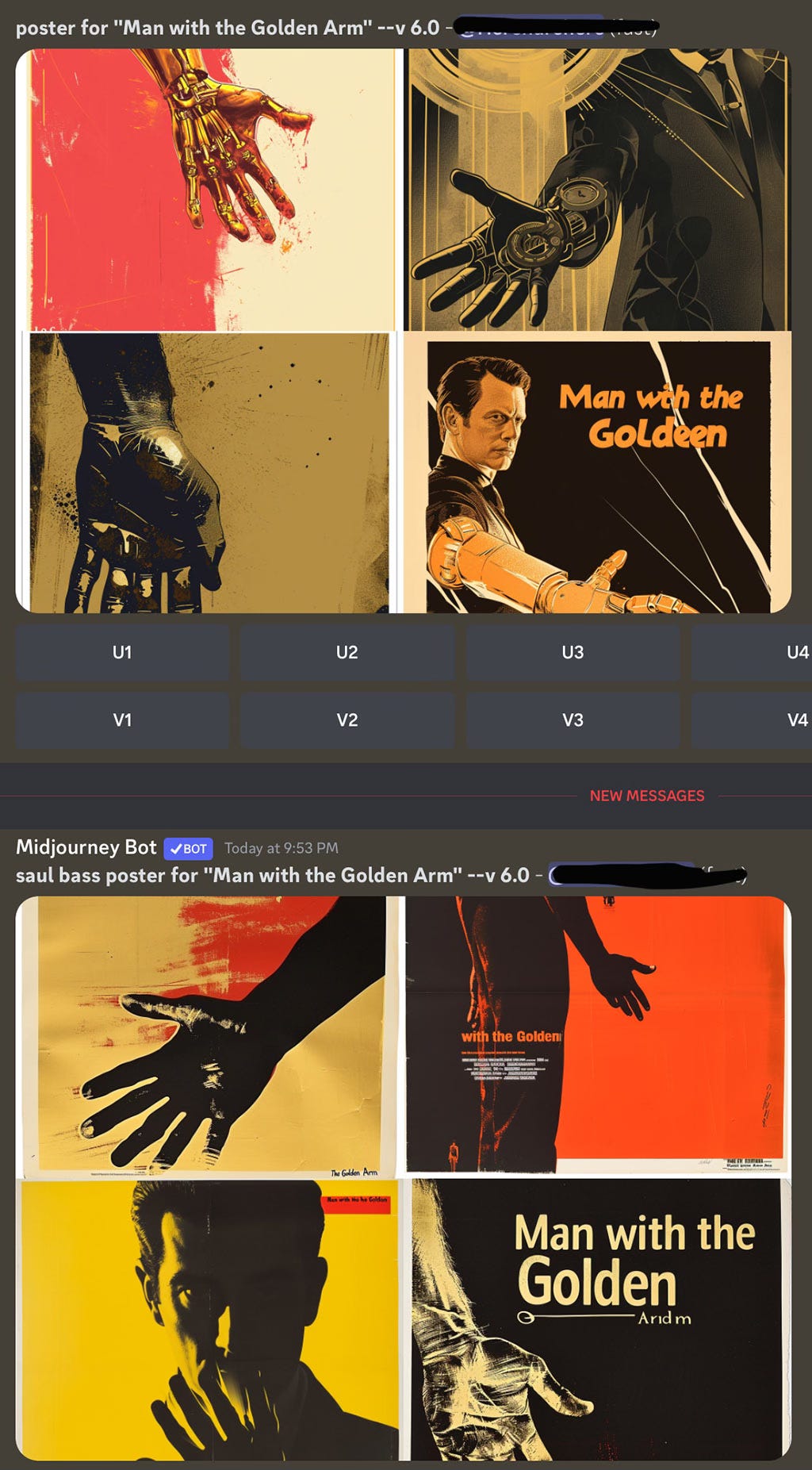
I also re-tested Midjourney on my own work and it remains blissfully ignorant of me (and Stefan Sagmeister, fwiw).
In short I don’t buy it that this is something that ordinary people should be worried about either for the possibility of having their own copyright infringed, or that the things they innocently generated are infringing someone else’s copyright.
Speaking of copyright …
If copyright infringement worries you that much, it’s already happening at a huge scale and you are also probably guilty. We do not live in an era of copyright purity where everyone knows about and respects copyright and AI systems are the evil danger that will bring us to unwittingly infringe on it.
Most people don’t know that:
Almost every meme you ever shared contains copyrighted material
Every time you use an image from TV or a movie to express your emotion or reaction to something, you infringe copyright
the vast majority of images shared on the internet and in personal messages are copyrighted material, including all those great cartoons and cute animals.
If a photographer takes a photo of you, you are not necessarily allowed to use that for every article, book jacket, profile, conference photo, promo, etc. The photographer owns the copyright to your image and you need to negotiate with them what you can use it for.
If an illustrator illustrates an article you wrote for magazine X, it does not give you the right to reuse it in magazine Y, on your blog, or in your presentations.
If you buy a physical piece of art, you have zero rights to display it anywhere other than your home/office, let alone make copies of it, digital or otherwise.
The list could go on. We all of us see multiple instances of copyright infringement every day, and most of us “share” those images, thus further perpetrating copyright infringement. Trying to find the source of many of these images is near impossible.
Given this, I maintain that AI generated images are a far better way to make your memes, birthday greetings, blog post/presentation/newsletter/zero-budget publication images than stealing them from the internet which is what most people currently do.
And if users are nervous about the slight chance that text-to-image generators will cough up a memorized copy of a photo, just don’t try to pass it off as your original work, or if an art director, don’t use AI instead of hiring a professional illustrator/photographer. The AI users most likely to be affected legally (if at all) by these anomalies are already hacks, charlatans and thieves.
How to fix AI’s little plagiarism problem?
The authors of the academic paper “Understanding and Mitigating Copying in Diffusion Models” take a logical approach to mitigation, based on what they think is causing the problem—fix the causes by
reduce multiples of duplicate images in the training data
reduce or eliminate multiple instances of duplicate captions
change highly specific captions to more general ones
reduce the number of very simple images
Marcus and Southen, however, go on at great length about how AI companies should license all of their training material, comparing them to Napster “because they sell subscriptions” to use their systems. But they are not Napster. They are not Getty Images. The “plagiaristic” anomalies do not mean that they are in the business of distributing copyrighted images. What the systems are doing is far closer to looking, or collecting in the way we all do on our systems and with Pinterest etc. (In fact Pinterest is far more insidious because people do share copyrighted material there, and, more irritatingly, there is a ton of misattributed material on there. This is not only a source of misinformation (no, Monet did not paint that crappy painting) but is potentially damaging to artists’ reputations when garbage is attributed to them. I have first-hand experience of this.) I pay a subscription to Midjourney so I can access their image generating system, not for streaming images from the internet.
Let’s imagine, for a moment, that it was legislated that AI systems had to license material in order to look at it and learn from it. What would this mean for search engines? What is the potential fall out for the rest of us? We might then have to buy licenses to look at images from big corporations and image platforms—it’s a logical money-making conclusion.
M&S make a big deal about big, evil AI and their profit-making dreams while conveniently ignoring the profit-making dreams of big, evil copyright holders like Disney, Marvel, et. al.
In my next post I will talk more about copyright giants, and the financial and “moral” protections of their material, while addressing another article about this same subject, that came out hot on the heels of “Generative AI Has a Visual Plagiarism Problem”.
If you want to compare resumés, experience, reputation etc. Gary Marcus has infinitely more cred in this area than I do. But does that stop me? :D
M&S talk about, and give examples from several other image generating models, as well as LLMs, but I only work with, and talk about, Midjourney.
In all examples I run the prompts a few times, although for the sake of space I show only one set of results from each test.
As a fan of yours, I am curious how you use the thousands of generative images you've been making. Are these simply like your own private personal art gallery? Or do you find them useful in your other work? Or are they trivial things you share with friends?
Great piece Marian! Thanks for sharing.